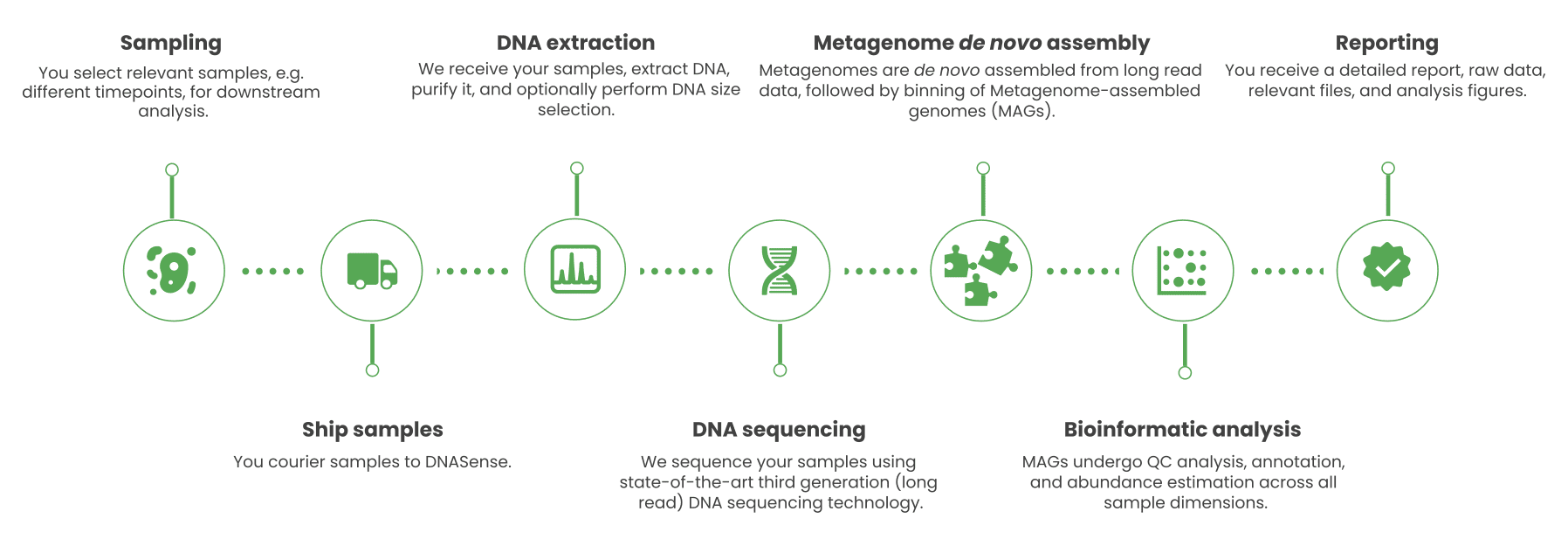
Advantages of Long-Read Sequencing
- Highly Contiguous Assemblies: Long-read sequencing produces longer DNA fragments, resulting in more complete genome assemblies and higher-quality MAGs compared to short-read methods.
- Bias Reduction: Eliminates common biases associated with short-read sequencing, such as GC-content bias and amplification bias, leading to more accurate abundance estimates.
- Enhanced Genome Recovery: Improved ability to reconstruct genomes from complex communities, including rare or previously uncharacterized organisms.

Sample Processing and DNA Extraction
-
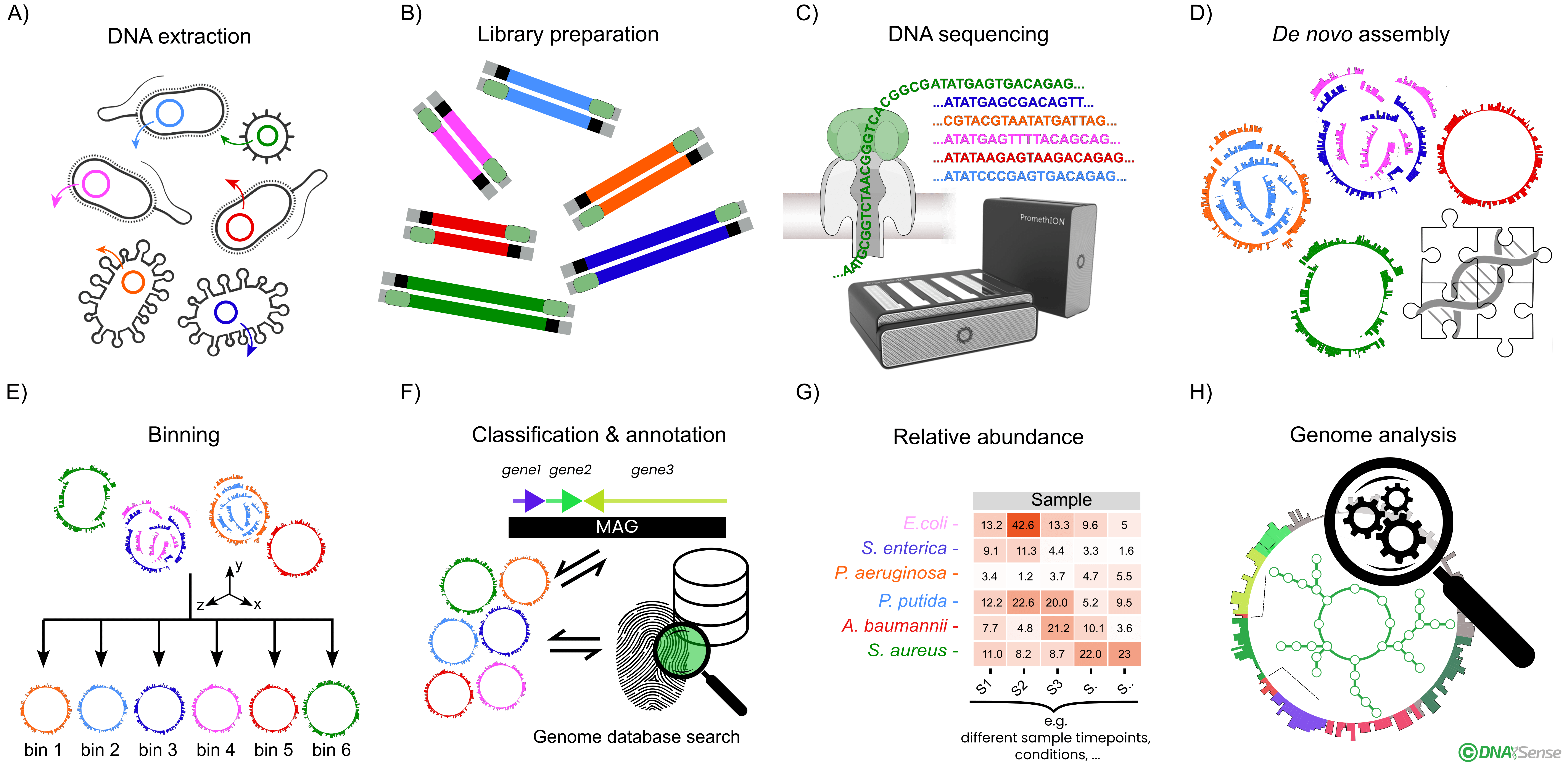
Customized DNA Extraction Protocols: Optimized for a wide range of sample types to minimize biases and maximize yield and purity, including high-molecular-weight (HMW) DNA.
-
Versatile Sample Handling: Capable of processing both low- and high-biomass samples using manual and automated methods.
Library Preparation and Sequencing
-
Long-Read Sequencing: Preparation of native DNA sequencing libraries for use on the Oxford Nanopore Technologies platform.
-
Hybrid Sequencing Options: Integration of short-read data (e.g., from Element Biosciences) for projects requiring enhanced genome polishing, particularly for eukaryotic organisms.
Data Analysis and Bioinformatics
-
Quality Control: Rigorous pre- and post-sequencing quality assessments to ensure data integrity.
-
De Novo Assembly: Generation of highly contiguous metagenome assemblies using advanced algorithms.
-
Genome Binning: Isolation of individual MAGs using machine learning models and experimental variables such as time points and treatments.
-
Taxonomic Classification and Annotation:
-
Classification against genome and rRNA taxonomy databases.
-
Gene annotation to identify metabolic pathways and functional potentials.
-
-
Abundance Estimation: Estimation of MAG relative abundances within your samples.
-
Advanced Bioinformatics Analyses: High-quality MAGs enable further analyses, including metabolic pathway reconstruction, functional characterization, and potential for metatranscriptomic profiling.
Sample Types We Handle
Our DNA extraction expertise allows us to process a diverse array of sample matrices, including but not limited to:
- Environmental Samples: Soil, wastewater, oil spills, marine and freshwater samples, sediments.
- Biological Samples: Prokaryotes, invertebrates, fungi, aquaculture organisms, animal gut contents (e.g., pigs, chickens, fish), plant materials.
- Clinical Samples: Biopsies (lung, colon, liver), swabs (skin, oral), feces, environmental DNA (eDNA).
- Industrial Samples: Bioreactors, microbial-induced corrosion samples, mining/drill site samples.
